新大陆杯 AI 竞赛开发文档
搭建 YOLOv5 环境
下载源码
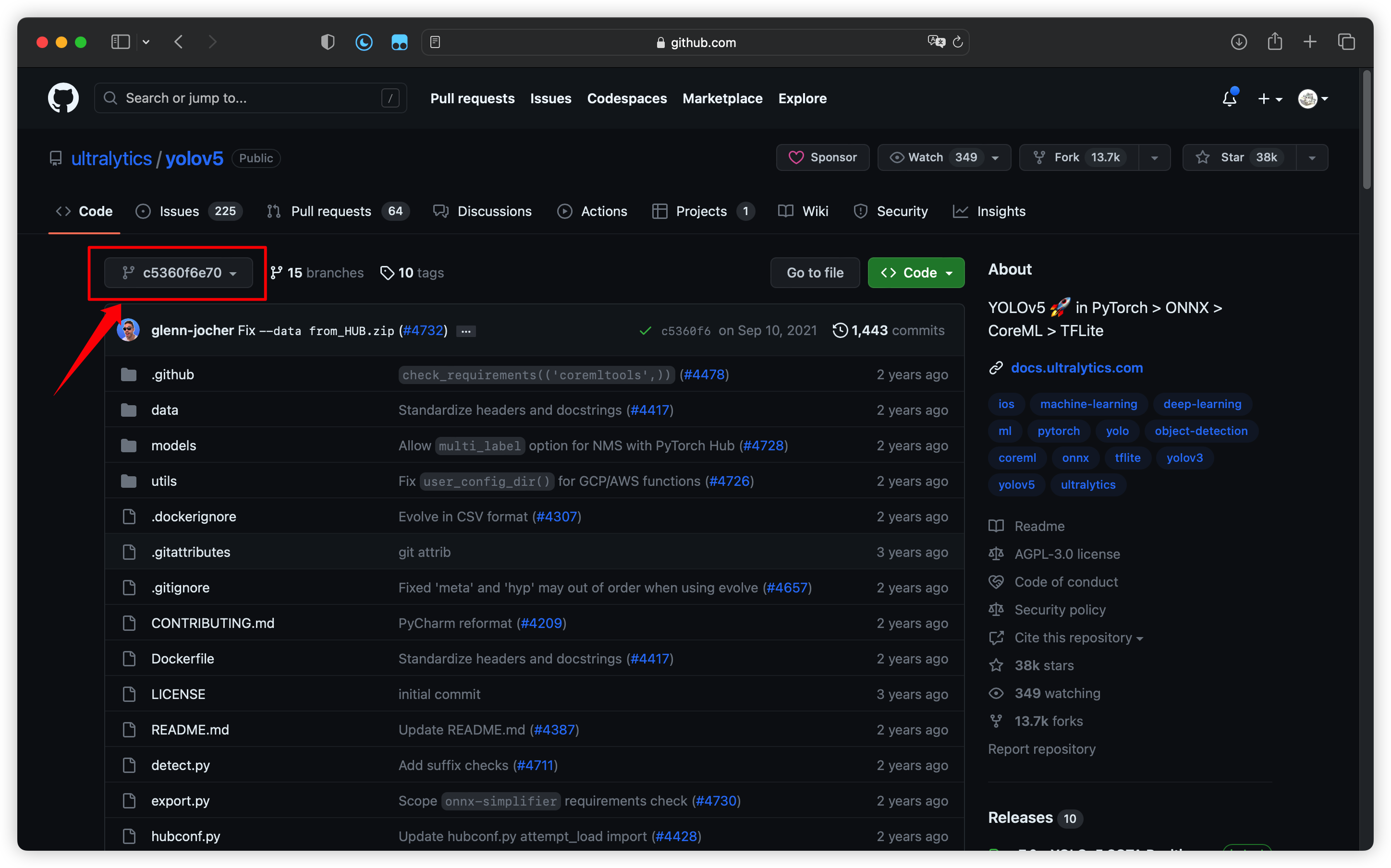
根据 RKNN-Toolkit 的要求(原文地址:Demo 运行步骤),必须使用 Commit ID 为 c5360f6e7009eb4d05f14d1cc9dae0963e94921 的YOLOv5 版本:
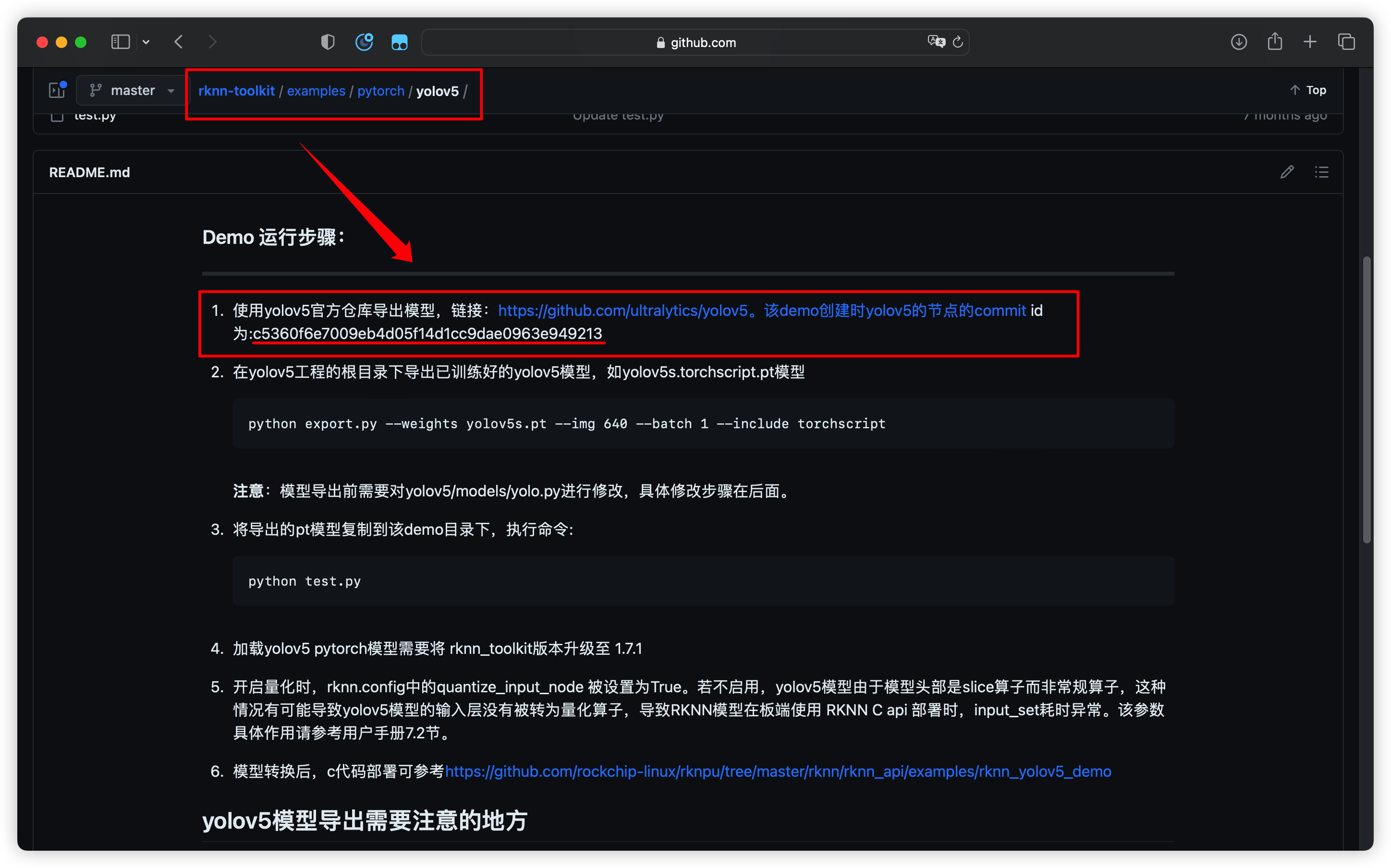
在 GitHub 中找到并下载该版本的代码:
安装依赖
由于包的兼容性问题,安装第三方包时需要严格遵守版本号 “==”,不可使用 ”>=”,且必须使用 Python3.7/3.8 版本,否则会导致各个包之间产生冲突无法正常运行。
此外还需更改 opencv-python 的版本为 4.1.2.30、torch 的版本为 1.7.1、torchvision 的版本为 0.8.2。
修改后的 requirements.txt 如下:
1 | |
使用命令 pip install -r requirements.txt 安装第三方库:
推演测试
执行 python detect.py 使用默认配置进行推演测试:
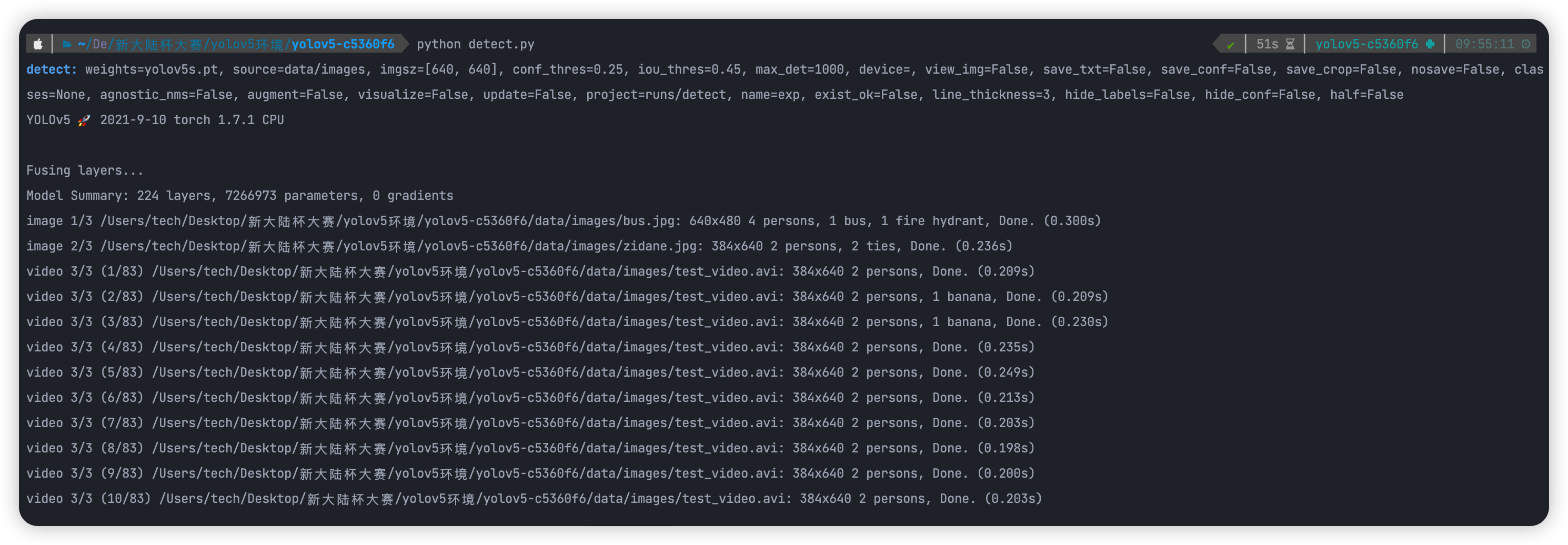
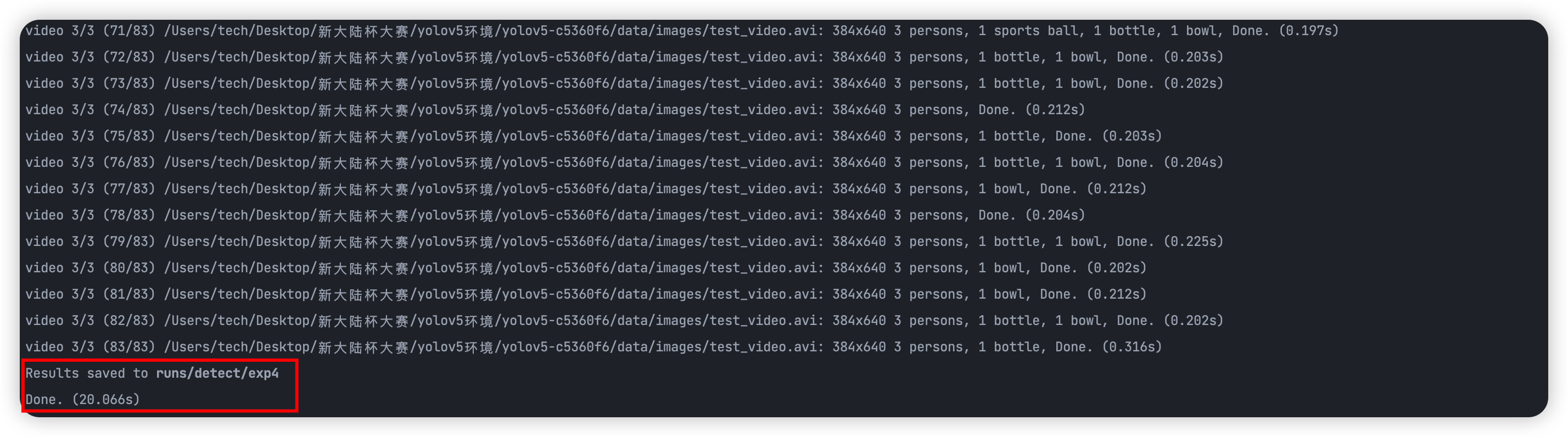
推演结果:

测试无误,环境搭建完成。
数据集处理
数据汇总
首先将官方数据集中 images 的照片全部放入到训练用图片文件夹中
然后将官方数据集中 annotations 的 xml 文件全部放入 xml 文件夹中
不用区分,直接汇总在一起。
数据划分与处理
然后运行用于划分数据集以随机生成生成训练集、验证集的程序,生成存储划分的 txt文件。
接着运行能够根据划分好的数据集 txt,来生成提取并存储图片对应路径和其识别框位置的 txt 文档的程序,其生成的 txt 文档在之后 YOLO 的配置文件就会用上。
以下为此程序的部分说明:
将 classes 设置为训练使用的类(下文只用于示例)
1 | |
类名使用的是 xml 文件中设置的类名如下:
1 | |
那么类别名就为 helmet,以此类推。
因为这一步写入的东西是路径,因此运行完后一定要辨认好生成的 txt 中路径和文件是否对应。
在口罩数据集中因为有部分图片为 png 文件,同时为了避免转格式引起的未知错误需要添加额外代码:
1 | |
配置文件
添加新训练配置文件,用于配置训练集、验证集的文件路径信息,使其指向我们之前生成的 txt 文档。文档内部的路径会指引其到真正图片的位置和生成存储的识别框坐标也会参与其中。
- 主要注意文件路径和类别的数量、类别的名称
- train、val、test 均是前文程序生成的对应的 txt 文档
- 一定要参考其他的配置文件进行修改,不同版本有区别
此次我们平衡了推理时延、识别置信度、部署设备等因素后选择 yolov5s,因此训练时我们要修改 yolov5s.yaml 的 nc 为需要训练的类别数量。
修改 data/hyps 中的超参数配置文件以进行数据增强等操作。
数据增强
在此次比赛中,要求只能使用官方的数据集,而我们要想要提高模型的精度那么对数据集也要提出一定的要求。
在我们使用的 YOLOv5 图像识别模型训练中要想在不增加额外数据集的情况下提高模型识别的准确度,可以采用离线数据增强和在线数据增强,来在当前数据集的基础上扩充数据集,以达到拥有更多复杂的数据集提高模型的准确度的目的。
离线数据增强就是修改当前存在的数据集通过变形、马赛克、复制粘贴等方式来扩充数据集,但是这样十分耗费存储和时间,因此我们选了了 YOLOv5 原生支持的在线数据增强,在线数据增强方式本质和离线数据增强一样,但是这一部分的操作是在训练时可以自动完成的,因此成为了当前比较合适的解决方法。以下为在线数据增强的相关的参数及其含义:
1 | |
在模型训练中进行数据增强有如下作用:
- 增加数据集的多样性,有助于提高模型的鲁棒性和准确率。
- 防止模型过拟合,通过对原始数据进行扰动,增加数据集的大小,可以有效地避免模型过拟合问题。
- 减少数据集中的类别偏差,通过变换数据集的类别分布,使得数据集中每个类别的样本数相等,从而避免类别偏差问题。
- 增加模型泛化能力,通过数据增强技术,更好地模拟现实场景下的多样性,从而使得训练出的模型更具有泛化能力。
- 降低数据标注成本,通过增加数据集大小,可以减轻数据标注人员的工作量,从而降低数据标注成本。
模型训练
训练参数
直接使用 train.py 进行训练显存占用较低,不能完全发挥 GPU 的性能,要充分利用 GPU 资源,需要使用如下命令:
1 | |
其中 -nproc_per_node 设置当前设备 GPU 的个数,后面跟上原本的训练参数,如对应的配置文件、预训练模型、训练方式、迭代次数、设备等‘
训练效果
运行如下:
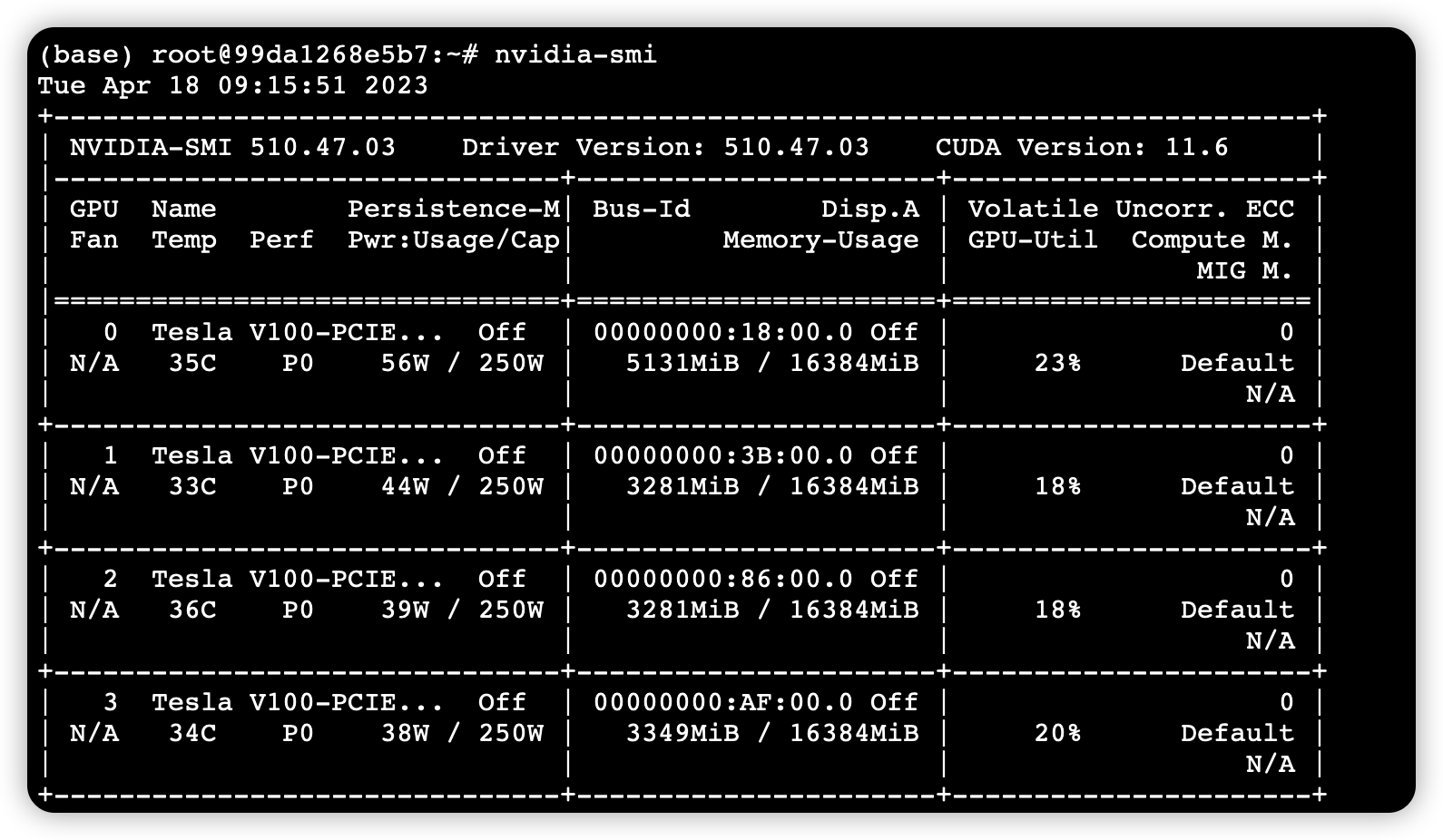
使用 python -m torch.distributed.launch –nproc_per_node 4 参数前训练时的 GPU 利用率:
使用 python -m torch.distributed.launch –nproc_per_node 4 参数后训练时的 GPU 利用率:
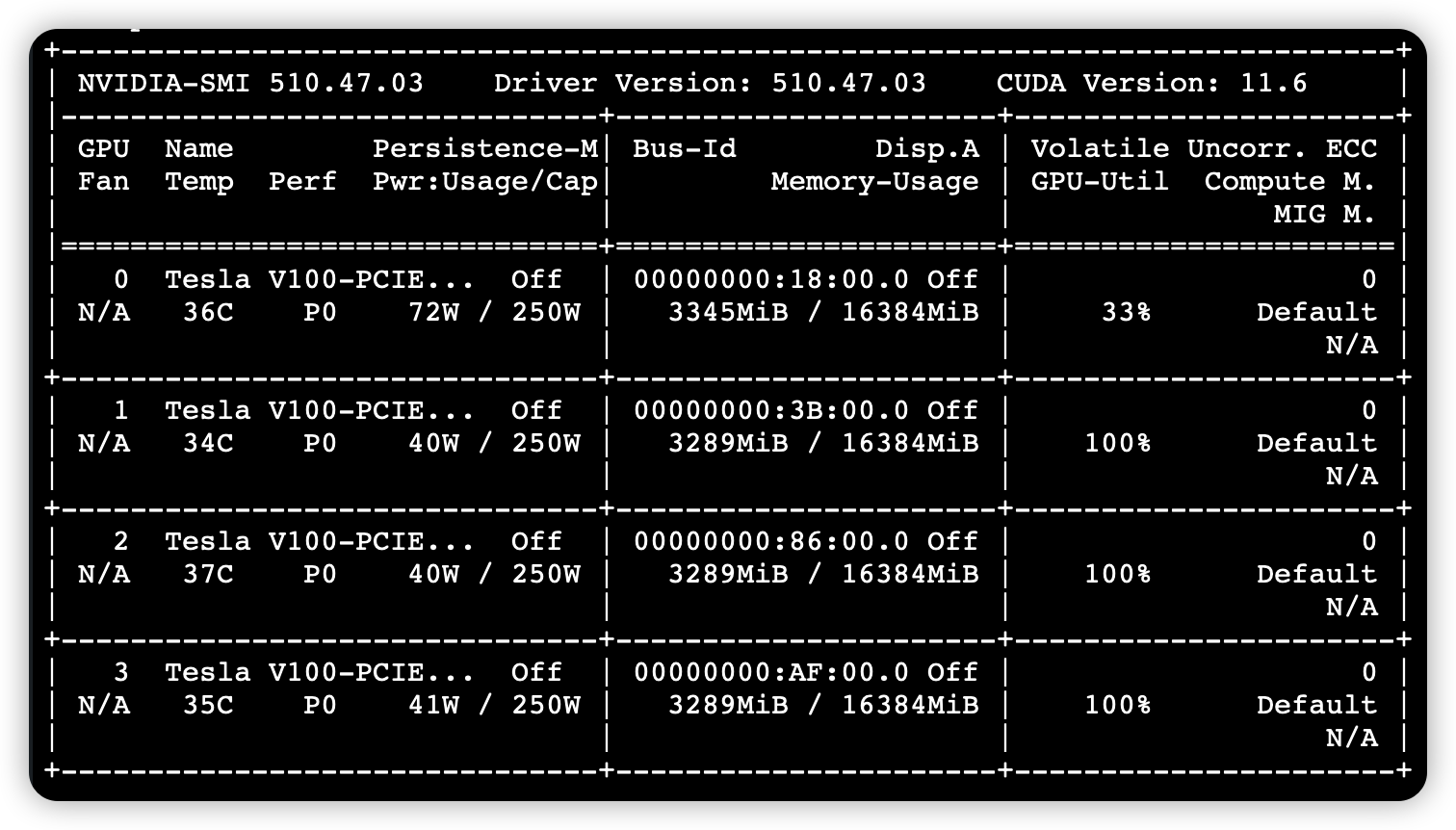
可以看到资源利用率的提升是非常明显的
模型导出
根据 RKNN-Toolkit 的要求(原文地址:Demo 运行步骤),必须修改 models/yolo.py 文件才能导出正确的模型文件具体如下:
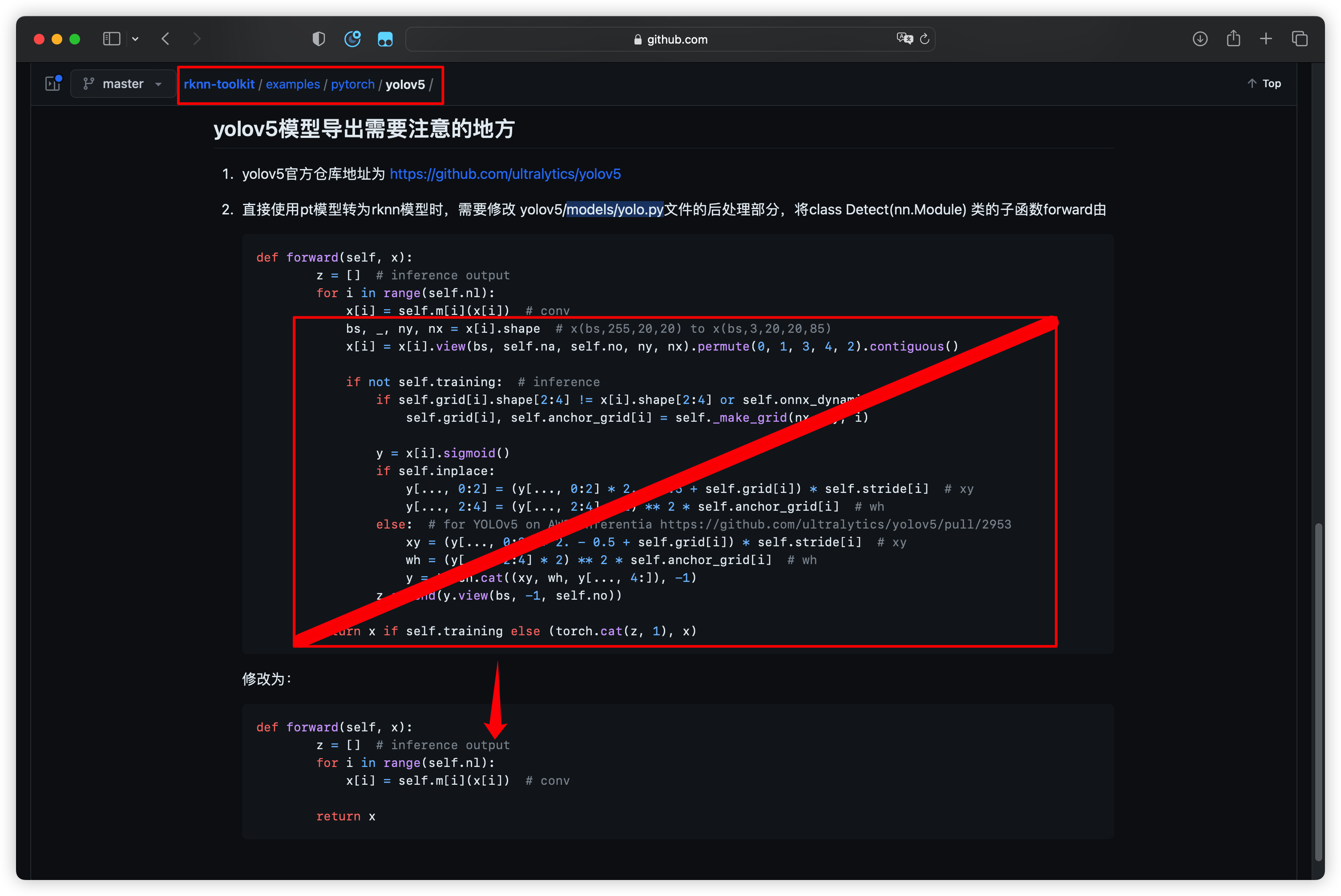
转为 ONNX
使用以下命令导出 ONNX 模型:
1 | |

转为 RKNN
此步需要安装 RKNN-Toolkit 工具,鉴于 RK3399Pro 上已经预装了该工具,就直接使用 RK3399Pro 进行转换了
将上一步导出的 ONNX 文件传到 RK3399Pro 上, 使用 RK3399Pro_npu(https://github.com/airockchip/RK3399Pro_npu) 驱动中提供的转换示例进行转换。
首先修改示例代码中的 ONNX 模型文件地址和适用平台:
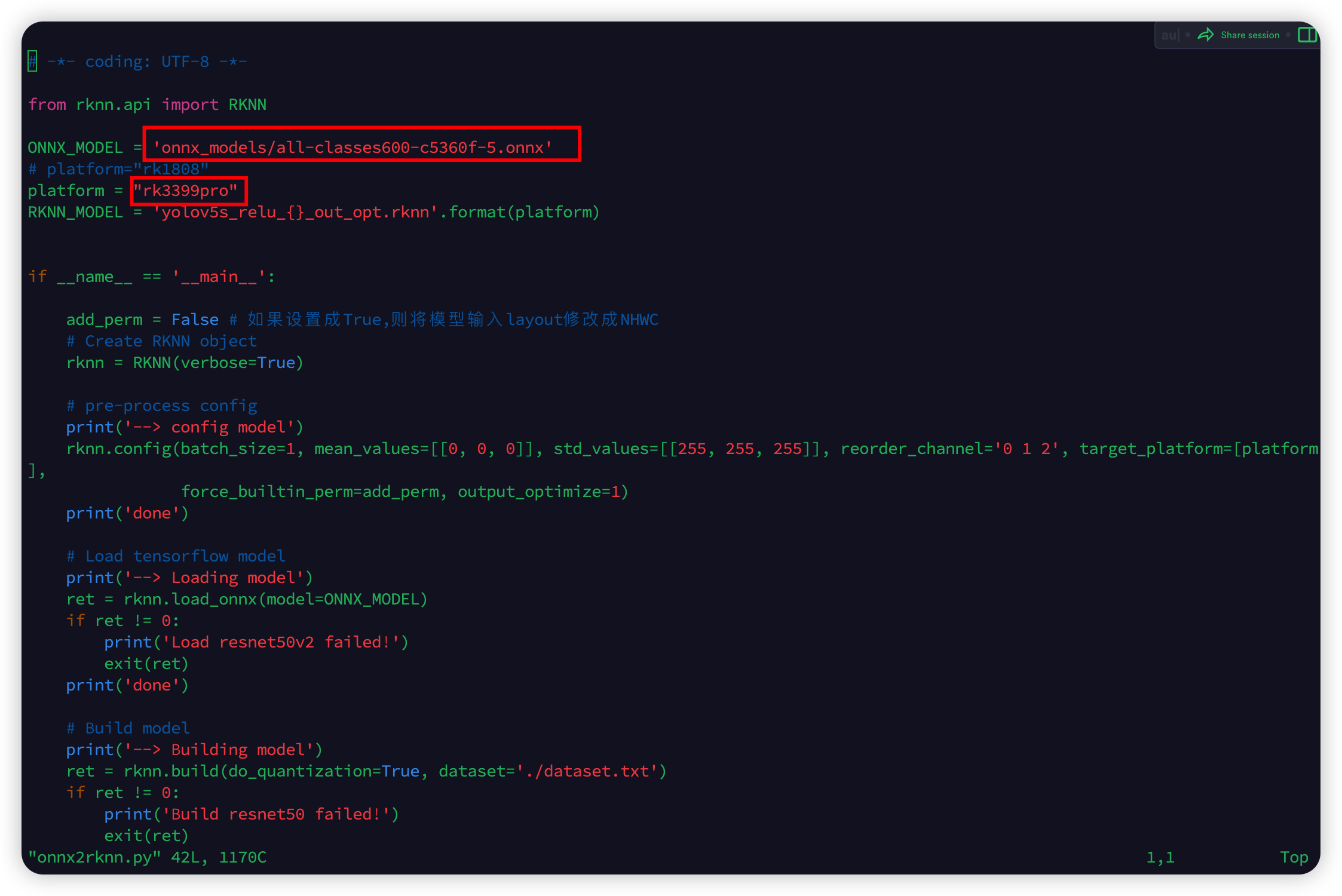
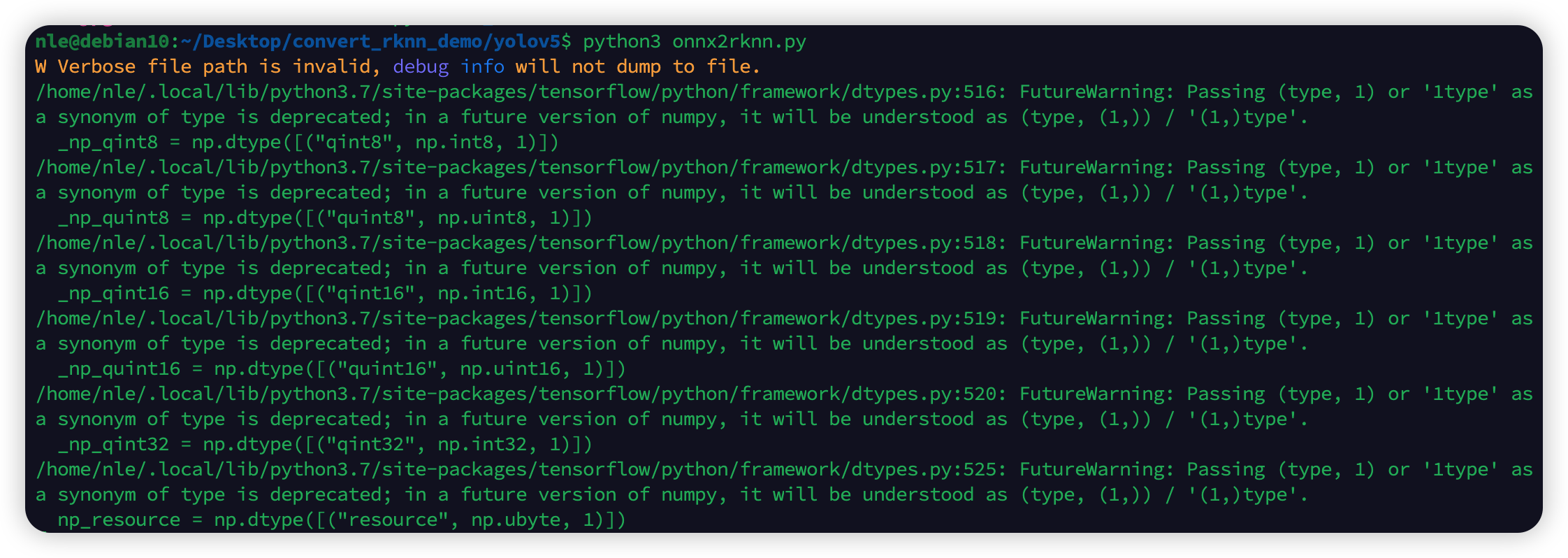
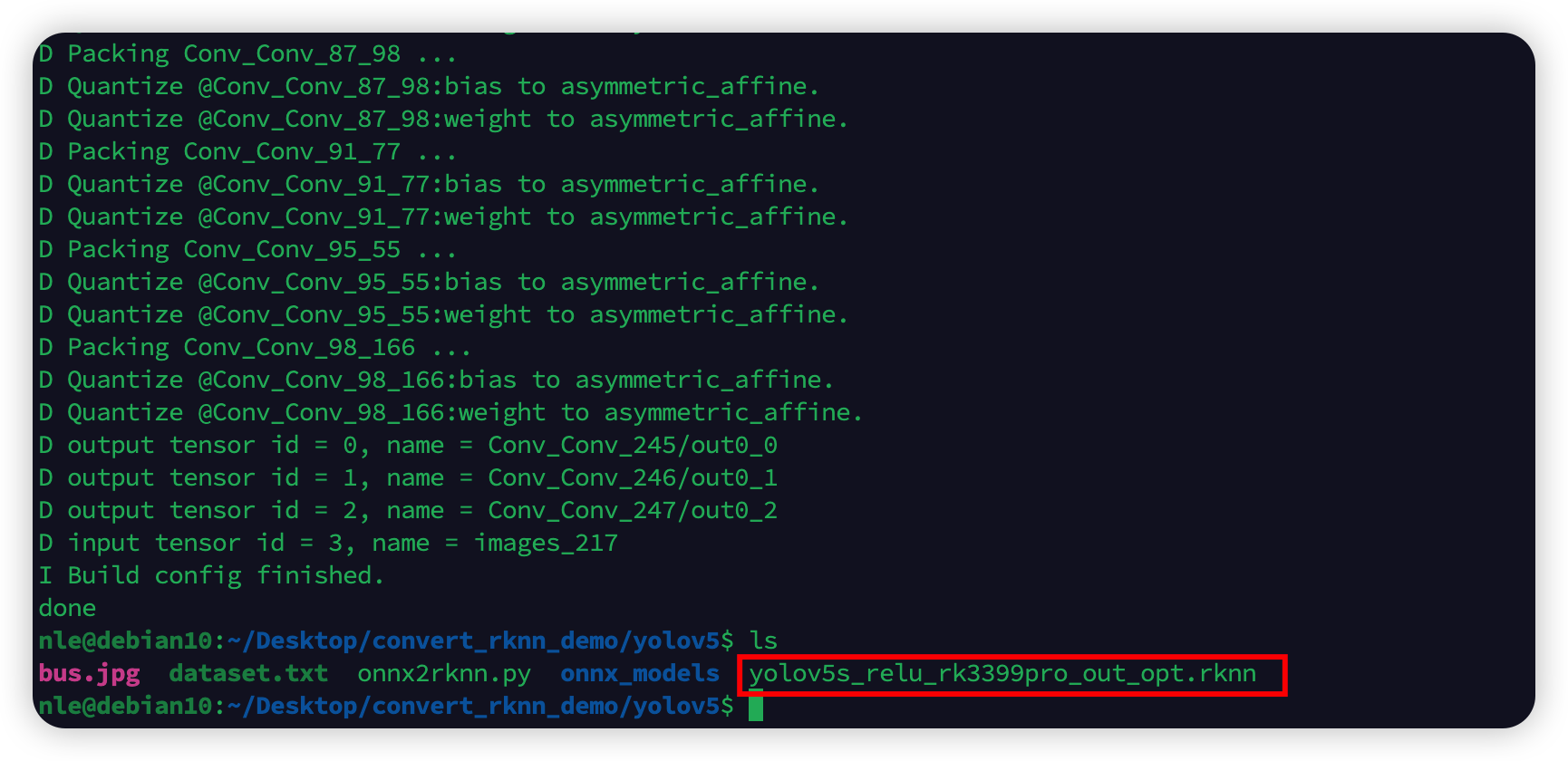
然后开始转换:
1 | |
编写检测代码 detect.py
代码讲解
代码的主要运行部分在 inference() 函数中,那此描述将以讲解 inference() 函数的内容为主。
在 inference() 函数中首先实例化一个 rknn 的对象再用此对象加载 rknn 模型并将其初始化,接着使用 opencv 提供的方法读取示例视频,获取其中的第一帧。
进入 while 循环中,这个循环中,每一次循环都是对视频中的一帧进行推理获取数据,直到整个视频的所有帧全部推理完毕才结束循环。
循环中,首先对从视频获取到的图片进行处理改变其颜色和分辨率使其适应模型的输入格式,接着就是对转换后的图片进行推理并记录推理的时间,在终端也可以观察到推理的次数和使用时间,推理完成后获得 outputs,将推理的输出数组 outputs 分为三份,再分别为其赋予新形状(即使用 reshape 对其进行处理),再依次放入 input_data 这一个 list 中。然后将 input_data 作为参数使用 yolov5_post_process() 函数来处理模型结果获取三个数组 boxes, classes, scores 分别为识别框的坐标、识别到的物品类别和此识别的置信度得分,并将处理时间和这三个数组在终端中显示。接着判断在此次推理中有无识别到对象,如果没有则抽取下一帧,有的话则根据 boxes, classes, scores 生成 anchor 和 label 并将其存入 temp 数组中,接着抽取下一帧继续前面的处理。
等到视频的所有帧都处理完成后,将 temp 数组转化为 json 格式存入 result.json 文件中,释放 rknn 模型,至此整个程序结束运行。
其他函数简介
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
这是一个对图像进行尺寸调整和填充的函数,以满足在模型中应用的要求。函数接收一个图像、一个新的目标尺寸和一个背景颜色。它计算出图像的比例缩放率,然后根据目标尺寸计算填充量,并在图像周围添加一个指定颜色的边框。最终,函数返回调整后的图像、比例因子和填充量。该函数通常用于目标检测或分类中对输入图像进行预处理以添加必要的填充。
def sigmoid(x):
此函数用来进行压缩,将其输入值映射到(0,1)之间,以便于对检测结果进行解释和分析。
def xywh2xyxy(x):
这个函数的作用是将目标框的表示方式从左上角坐标和宽高表示转换为左上角坐标和右下角坐标表示。
def process(input, mask, anchors):
该函数能够将模型输出的特征图转换为目标检测的预测结果,计算出每个检测框的位置、置信度和类别概率等信息,并输出结果供后续的操作和可视化使用。
def filter_boxes(boxes, box_confidences, box_class_probs):
这个函数的作用是对目标检测算法输出的边界框、置信度和类别预测进行过滤和筛选,返回符合条件的边界框、类别和置信度。
def nms_boxes(boxes, scores):
这个函数是对目标检测的输出结果进行非极大值抑制的操作。在目标检测任务中,检测算法往往会搜索图像中所有可能存在的目标,并生成一系列框(box)和每个框的置信度(score)。由于同一个物体可能会在不同位置和尺度上生成多个框,为了避免重复检测同一个物体,需要对生成的框进行NMS操作,从而得到保留的、最具代表性的那些框。
def yolov5_post_process(input_data):
这个函数是对 YOLOv5 检测结果的后处理流程进行了实现。它的主要作用是将 YOLOv5 的输出处理成一组相应的检测框(bounding box),以及相对应的概率和类别信息。总的功能就是将 YOLOv5 模型的输出处理成可用的检测结果,并对其进行一定的筛选和去重处理,以达到更好的准确率。
def draw(image,boxes, scores, classes):
这段代码是一个用于将检测结果在原图上画出来的函数,并生成比赛需要的anchor和label并返回。函数接收四个参数:原图像、检测框、检测得分和检测类别。函数遍历每一个检测结果,使用 cv2 库在原图上画出对应的矩形框并添加相关文本信息。最后,函数返回所有检测框的坐标、检测类别和画完框后的图像。
截取部分关键代码如下:
1 | |
推演视频
推演方法
在 RK3399Pro 上运行上一步的 detect.py 程序
1. 在最上方找到 VID_PATH 变量,将其修改为需要检测的视频的路径;
2. 找到 RKNN_MODEL 变量,将其修改为需要加载的模型的路径;
3. 在控制台上运行 python detect.py 即可运行并生成 result.json。
推演过程
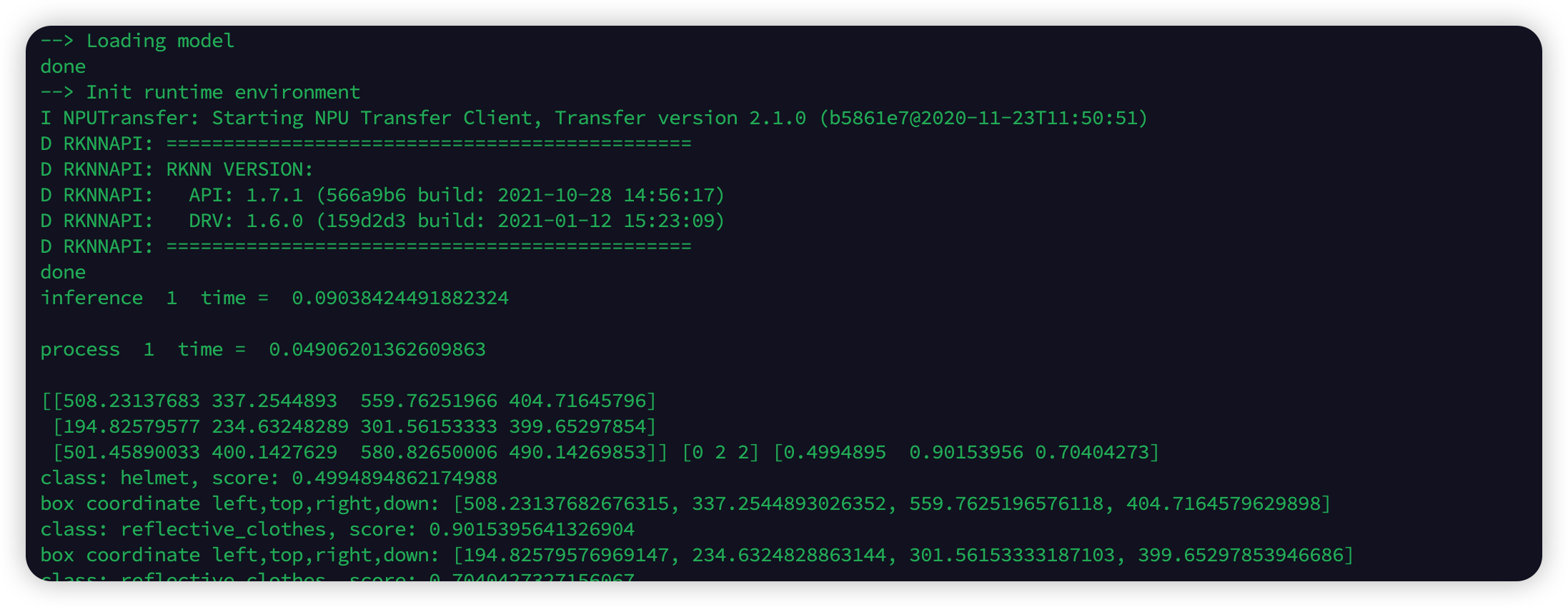
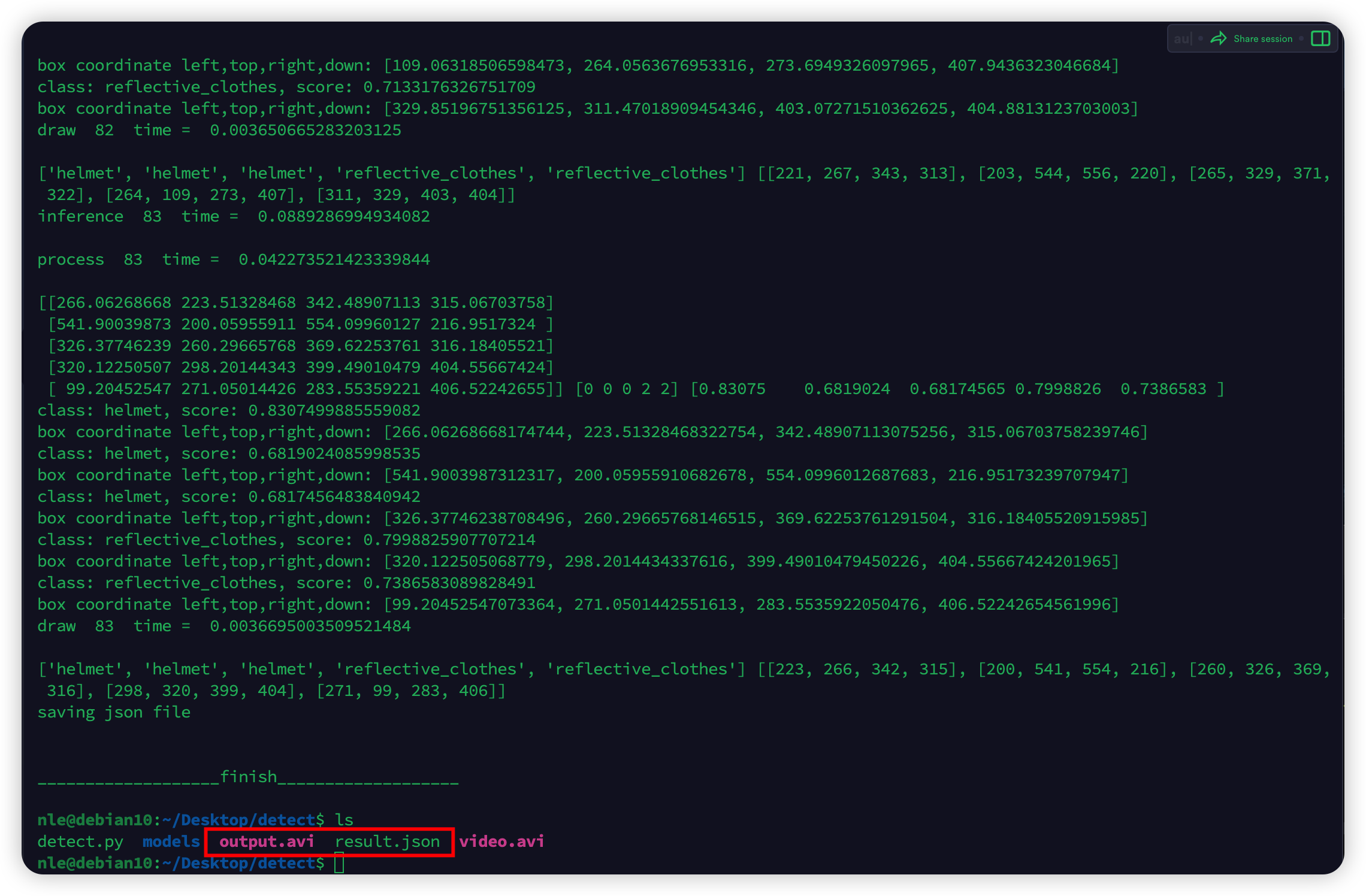
推演结果
截取部分 result.json 如下:
1 | |